
![]() ∥
∥ ![]() ∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
Text SAM是一個開源影像分割模型,可以使用自由文字來擷取出影像上的特定地物類別,它的功能是結合Grounding DINO by IDEA-Research和Segment Anything Model (SAM) by Meta兩個預訓練模型。Grounding DINO是一個物件偵測器,可以根據文字提示找到物件及外框(bounding box),而搭配Segment Anything Model找對該物件的邊界遮罩(masks),進而透過ArcGIS Pro軟體傳換成GIS多邊形圖層(polygons),這個模型可以用於偵測航遙測影像上的建築物、車輛、飛機、船隻、太陽能電池板等常見的地物類別,地面解析度越高預測效果越好。
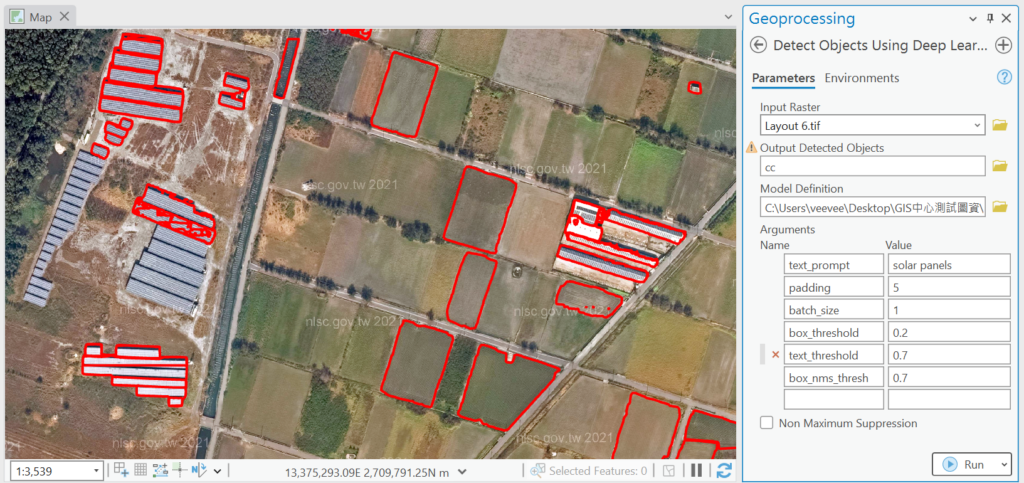
ESRI. ArcGIS Pro 3.x已經將Text SAM模型整合到Image Analyst擴充模組內,詳細內容可以參閱: https://www.arcgis.com/home/item.html?id=8df3bf4167bc4c7b967f677f8b362ec3