
![]() ∥
∥ ![]() ∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
專題題目:基於 LLaVA 多模態模型方法評估行人空間品質
實習學生:鄭怡文 (國立政治大學地政學系)
指導老師:郭巧玲 助研究員
1.研究背景與動機
台灣的行人空間,包括人行道與騎樓,常常因臨時停放的車輛、私人商家攤販使用或公共設施設置,增加了行人的不便和意外風險。本研究旨在探索如何利用生成式AI方法—LLaVA(Large Language and Vision Assistant) (Haotian Liu et al., 2023)多模態模型進行Image to Text訓練任務,達成自動化評估行人空間品質,提供可步行性(Walkability)分析參考,希冀提升行人空間的品質和安全性。
2.研究流程與方法
本次訓練模型的影像來自「平安走路許願帳戶」(韓中梅、許武龍,2022),該專案以公民科學的精神,透過自發式地理資訊(Volunteered Geographic Information,縮寫VGI)方式蒐集各地的行人環境影像,在群眾標註上以CC0版權方式公開使用。
相關的研究流程與地圖網站設計架構可參照圖1,包含訓練資料取得、行人空間品質指標設計、資料預處理與標註、行人空間品質模型建構(LLaVA)、WebGIS架設、行人空間品質分析等步驟。其中的評分指標包含「是否設置人行空間」、「保護性」、「占用情形」、「行人被迫繞道、碰到的最大風險」、「視線遮擋」等五項。
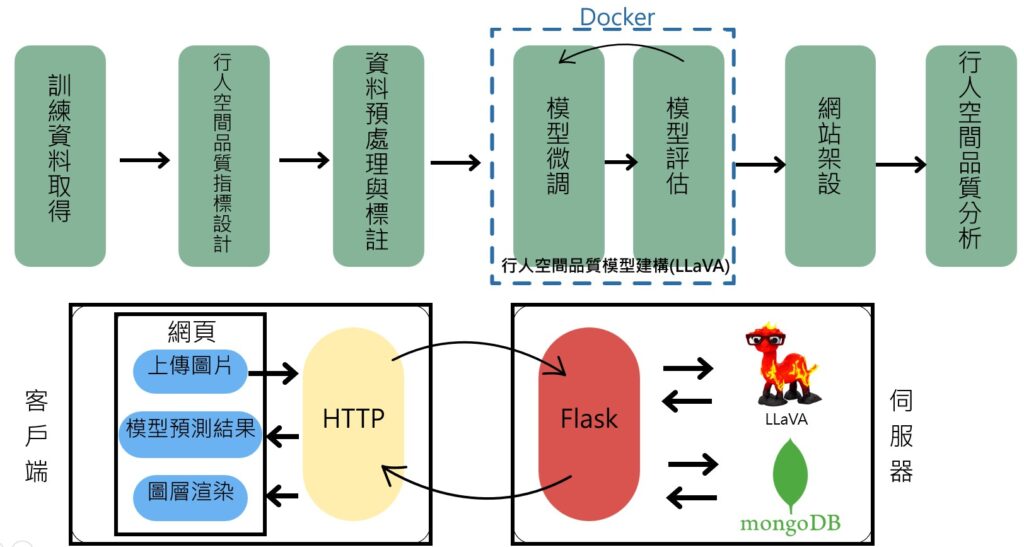
3.LLaVA 模型結構與訓練
4.行人空間評估WebGIS應用
使用開源Mapbox地圖服務框架(Mapbox, n.d.)建立網站,設計規劃上以示警分析的方式呈現,同時也讓一般民眾嘗試了解自家周圍或上班區域的行人空間品質。
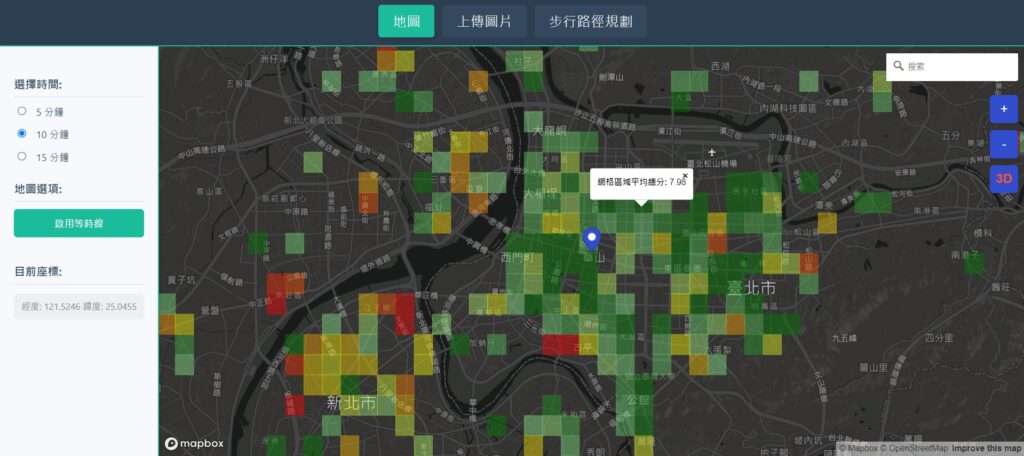
地圖網站透過500*500公尺網格進行顏色分級,顏色越綠代表行人空間越友善,越橘或越紅代表越不友善(圖2);放大至街道尺度時(圖3),一樣可看到用顏色進行分級的點,每一個點可以進行pop-up資訊呈現。
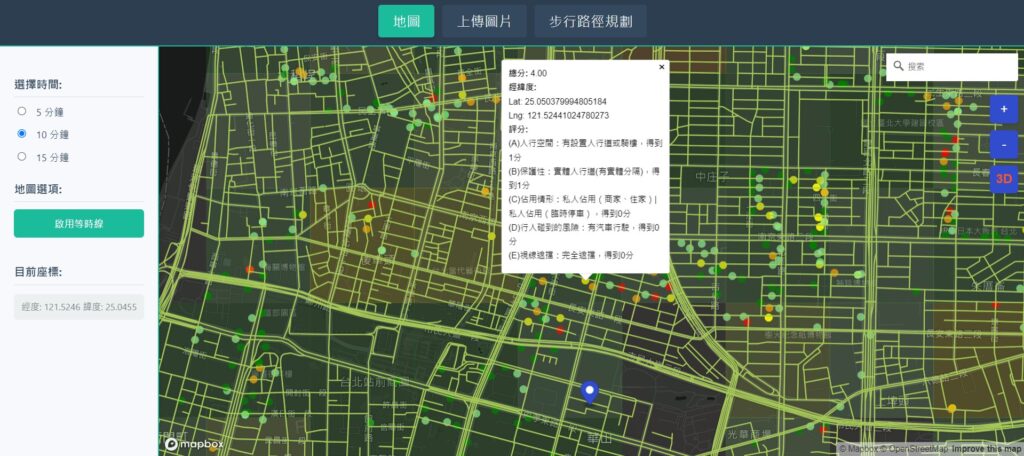
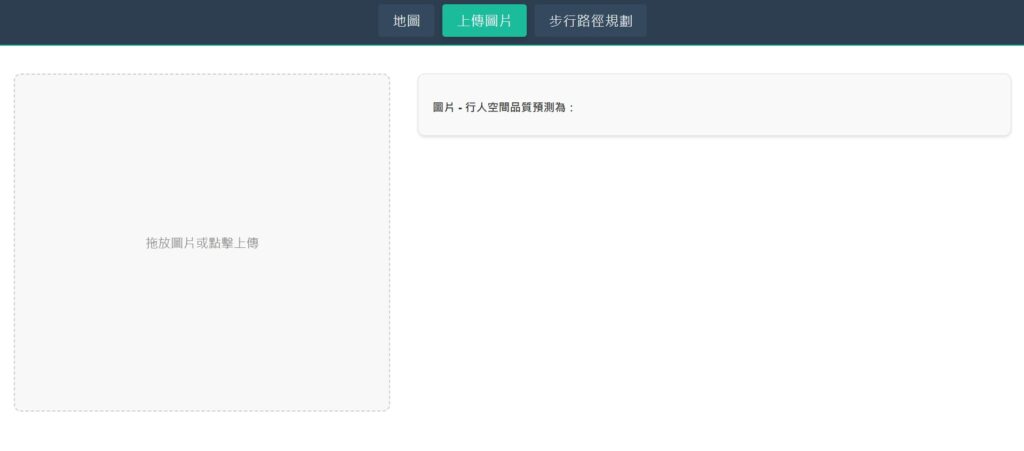
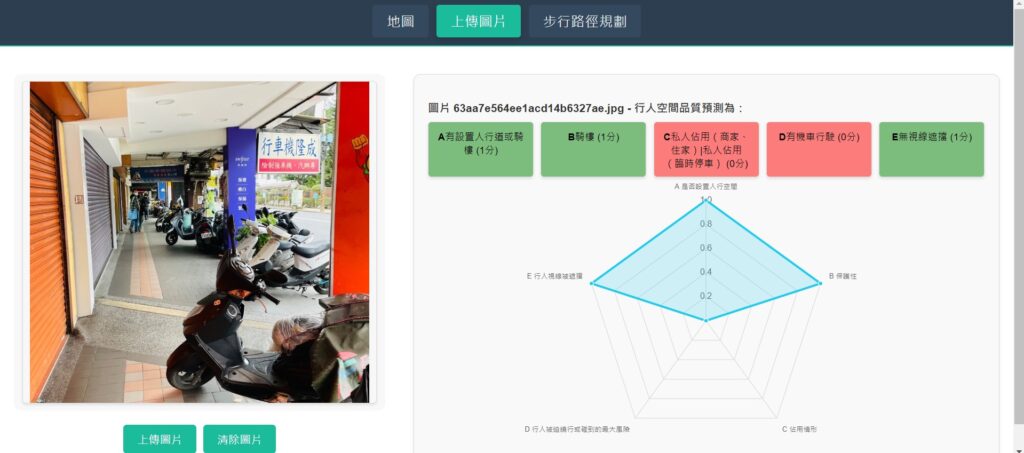
網站也提供圖片上傳,進行行人空間品質評估功能,使用者可以透過點擊或拖曳方式選擇圖片(圖4),按下「上傳圖片」按鈕,圖片將會回傳至後端進行行人空間評估文字生成,再將結果回傳前端顯示在網站上(圖5),進行A~E五個項目的評分顯示。
5.結論與後續目標