
![]() ∥
∥ ![]() ∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
專題題目:大型語言模型應用於古文命名實體識別 – 以明實錄為例
實習學生:歐祐辰(國立中央大學資訊工程學系)
指導老師:蔡宗翰 研究員
蔡宗翰研究員所指導暑期實習生歐祐辰同學所進行的研究主題為大型語言模型應用於古文命名實體識別。由於古文命名實體識別相比今文要面對更多挑戰(實體結構的多樣性、實體的多義性和上下文依賴性),難以人工大量標註資料,因此本研究專題以有標點的明實錄文本為例,透過大型語言模型與上下文學習,生成標註資料用以訓練一個機器學習模型 此模型可以根據輸入的文本內容, 識別正確的人名 、地名、機構名等命名實體 。以下簡述其方法與成果:
1.提示工程
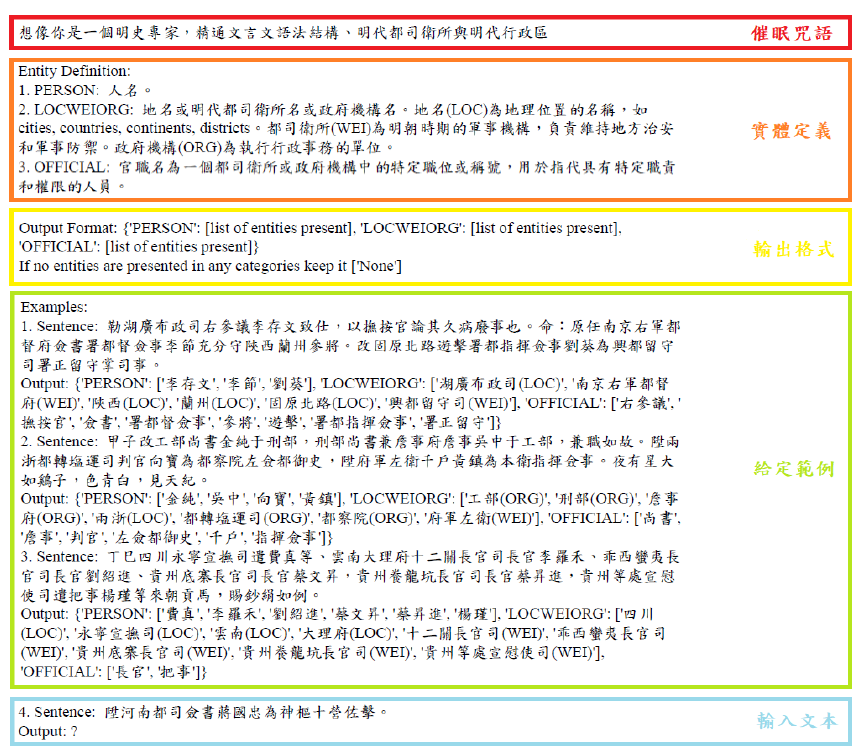
此階段將設計提示讓大型語言模型經上下文學習後生成標註資料,其中又可以細分為以下步驟:
a.催眠咒語:在設計的提示中,一開始以一句催眠咒語作為開頭,讓語言模型知道接下來的文本會是明代的古文,會需要分析語法結構、明代都司衛所與明代行政區。
b. 實體定義:下一步定義命名實體類別 ,一共 5種,分別為人名 (PERSON)、地名(LOC)、衛所名 (WEI)、官署名 (ORG)與官職名 (OFFICIAL),其中將地名、衛所名、官署名合併在相同類別,並在每個 命名實體後再以小括號細分為地名、衛所名或 官署名 ,目的是為了降低大型語言模型重覆標記的可能性 。
c.輸出格式:接著為避免大型語言模型輸出的格式不一影響後續處理效率, 給定輸出格式為一個python的字典樣式 若輸入段落有某類別沒有命名實體則輸出 [‘None’]。
d.給定範例:在提示的最後,我們給定 3個具體例子,希望大型語言模型能夠在這幾個範例學習到命名實體識別的能力。
e.輸入文本:將上述的提示統整,並再加入欲命名實體識別的段落後,就可以送進大型語言模型並得到其輸出結果。
2.後處理修正
由於大型語言模型藉由上下文學習的能力有限,在某些段落會犯些特定錯誤,因此我們仍需要經過後處理,利用一些 規則將錯誤給修正。這個階段同時也 將大型語言模型的輸出放回原始文本,以利後續模型訓練。

3.模型訓練
將前述後處理修正後的文本轉換為序列標記訓練資料的格式。序列標記任務是在自然語言處理中典型解決命名實體識別的方法,訓練的框架採用flairNLP Encoder使用現階段已知開源的最強古文預訓練模型 Jihuai/bert-ancient-chinese Decoder則為 flairNLP提供的 Bi-LSTM與 CRF。
4.實驗結果
首先抽樣500段明實錄文本作為訓練資料 (使用 GPT4生成 ,且經後處理修正 )後切分訓練集:驗證集 = 91,並人工標註另外102段作為測試集,經訓練後最好的模型表現在測試集可以達到近九成的Micro-F1分數。本專題展現了現今蓬勃發展的大型語言模型之無窮可能性,期許有更多困難的任務能夠在無標註資料的情況下透過大型語言模型解決。