
![]() ∥
∥ ![]() ∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
專題題目:史記人名鏈結系統
實習學生:陳柏瑋(國立中央大學資訊工程學系)
指導老師:蔡宗翰 研究員
蔡宗翰研究員所指導暑期實習生陳柏瑋同學所進行的研究主題為史記人名鏈結系統,從過去實作經驗發現,透過數位人文方法來分析史籍資料時,時常遇到許多不同人物但有相同姓名的問題,使得人物資料分析與關連上產生混淆;以《史記》為例,死後被追諡為「武公」的人物,有非常多位,例如晉武公、曹武公、燕武公、趙武公、陳武公、衛武公、鄭武公、宋武公、杞武公、秦武公、魯武公和齊武公等人物,而正確的人物鏈結,通常必須透過人工閱讀上下文語意來得知。於是本研究專題透過機器學習,訓練一個機器學習模型,此模型可以根據給定的人物資料以及輸入的文本內容,鏈結及識別正確的人名。簡要步驟與成果介紹如下:
1.資料爬取:
透過「中國哲學書電子化計劃」網站,爬取史記原文的文本及查詢維基百科,建立史記人物資料庫。
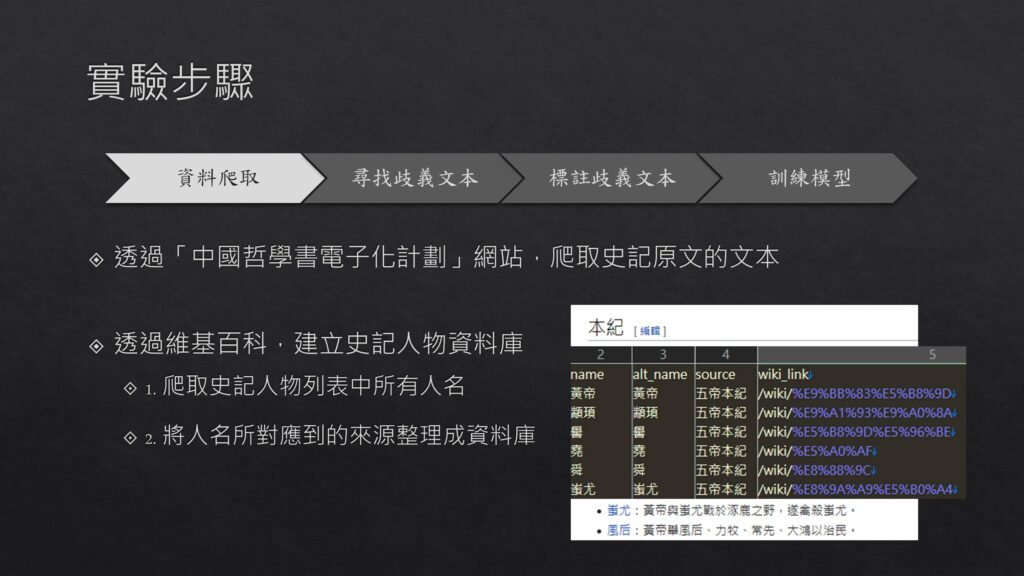
2.尋找歧義文本:
在人物資料庫中,針對「王、公」等廟號,找出可能產生歧義的人物資料及於史記中「本紀、世家、列傳」的文本,搜集包含歧義,卻不含全名的段落。

3.標註歧義文本:
若是「本紀」,記載的多是某國歷史,在該文本中出現的高機率為該國的君主,直接進行標註,如果是史記作者使用簡寫的廟號 (武公、武王) 的情形,通常是前面已經提過此人物的全稱 (秦武公、周武王),後則改用簡寫,透過以上原則,撰寫出程式,對文本進行標註。

4.訓練模型:
訓練使用 BERT 模型,共 10 個 epoch,並使用負採樣 (negative sampling) 做為資料增量的手段。獲得訓練集 (train) 資料的準確率為92%,測試集 (test) 資料的準確率為82%的成果。

5.實證案例分享:
使用模型方式以梁襄王的資料為例,在模型的訓練資料中沒有梁襄王的資料,此處的梁襄王,指的是魏襄王。由於戰國時魏惠王遷都大梁,魏國也稱梁國。模型能夠在這個例子中判斷正確,表示模型有學到「魏」與「梁」之間的關係。

資料提供:陳柏瑋 說明文稿:陳柏瑋、羅翊文、廖泫銘