
![]() ∥
∥ ![]() ∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
∥ 中研院 ∥ 人社中心 ∥ 繁體中文 ∥ English
專題題目:基於大語言模型技術之中文學術文獻時空資訊擷取
實習學生:鄭卓欣 (國立臺北大學資訊工程學系)
指導老師:蔡宗翰 研究員
1.研究背景與動機
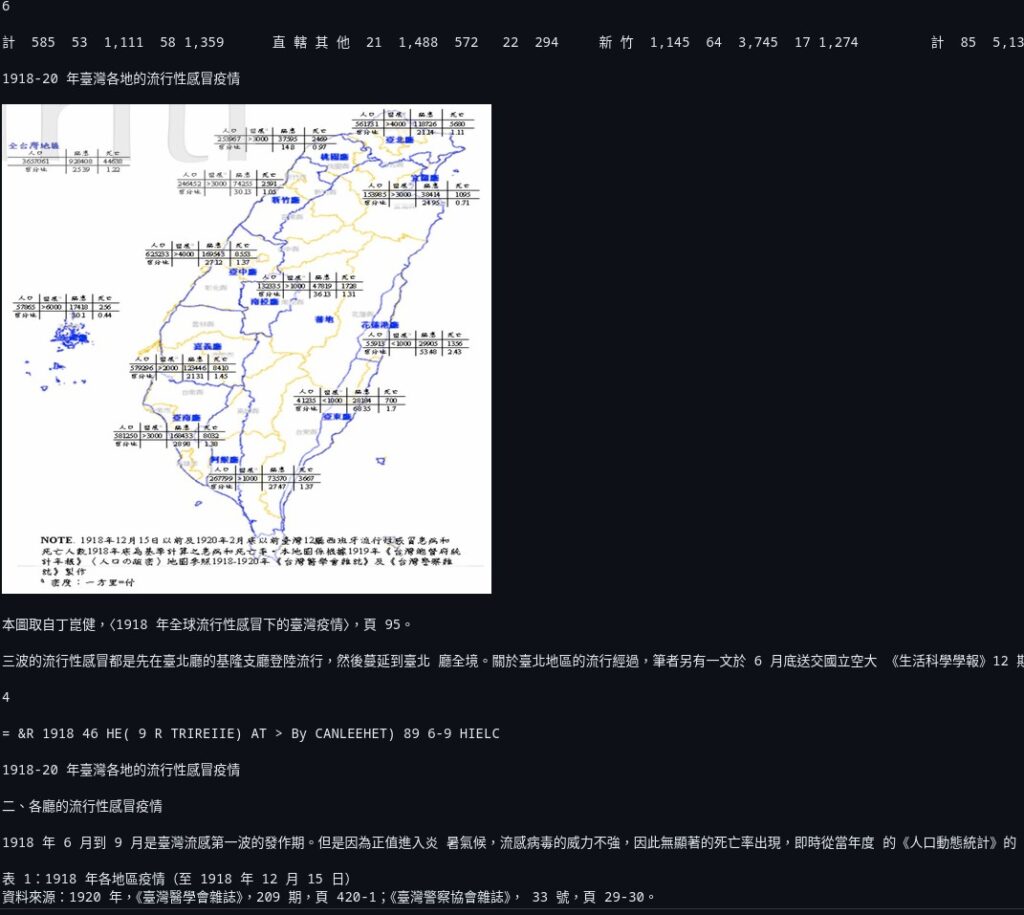
隨著數位化浪潮的推進,學術研究文獻數量呈現爆炸性成長,傳統的資訊檢索技術已難以應對日益龐大的文獻資料。特別是在地理學等涉及大量圖表、地圖的學科領域,現有的檢索系統存在明顯不足:
2.研究方法與步驟
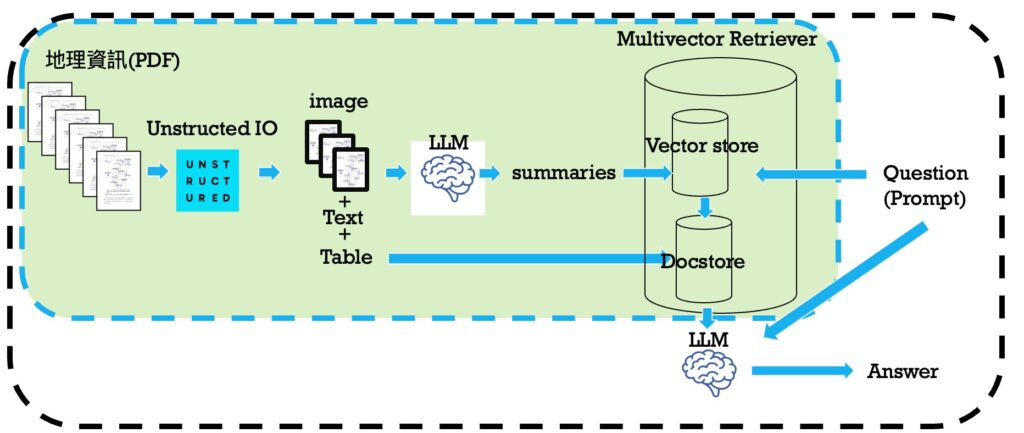
本研究採用 Retrieval Argumented Generation (RAG) 架構,並以 Multivector Retriever 為核心,其整體結構如下:
a.文獻預處理:
◦利用 Unstructured IO 將 PDF 轉換成有意義的表格數據、內文和圖。 主要分割方式採用 YOLOX 模型。
b.資訊提取與儲存:
◦將表格數據、內文和圖利用大語言模型做總結。
◦總結內容透過 Embedding model 轉化成向量並放入向量空間(Vectorstore),而對應的表格數據、內文和圖則存入資料庫(Docstore)。
◦向量空間會儲存對應資料的 ID,以便後續聯繫。
c.檢索與回答:
◦當問題傳入 Multivector Retriever 時,會先利用 Embedding model 預處理。
◦預處理後的向量會與 Vectorstore 中向量進行相似度搜尋,找出相似的向量。
◦接著利用 ID 從 Docstore 中提取相關資料,並將問題與提取資料一併傳入 LLM 中生成答案。
d.使用 ChatGPT-4o 來處理文字和表格。
3.系統架構圖 (Multivector RAG Pipeline)

4.預期應用潛力
結論:
本研究利用大語言模型技術和多模態機器學習模型,建構一個能夠自動化處理中文地理學文獻的智能系統。透過此系統,期望能夠解決傳統檢索方法在處理多模態資訊和時空資訊上的不足,進而提升學術研究效率。